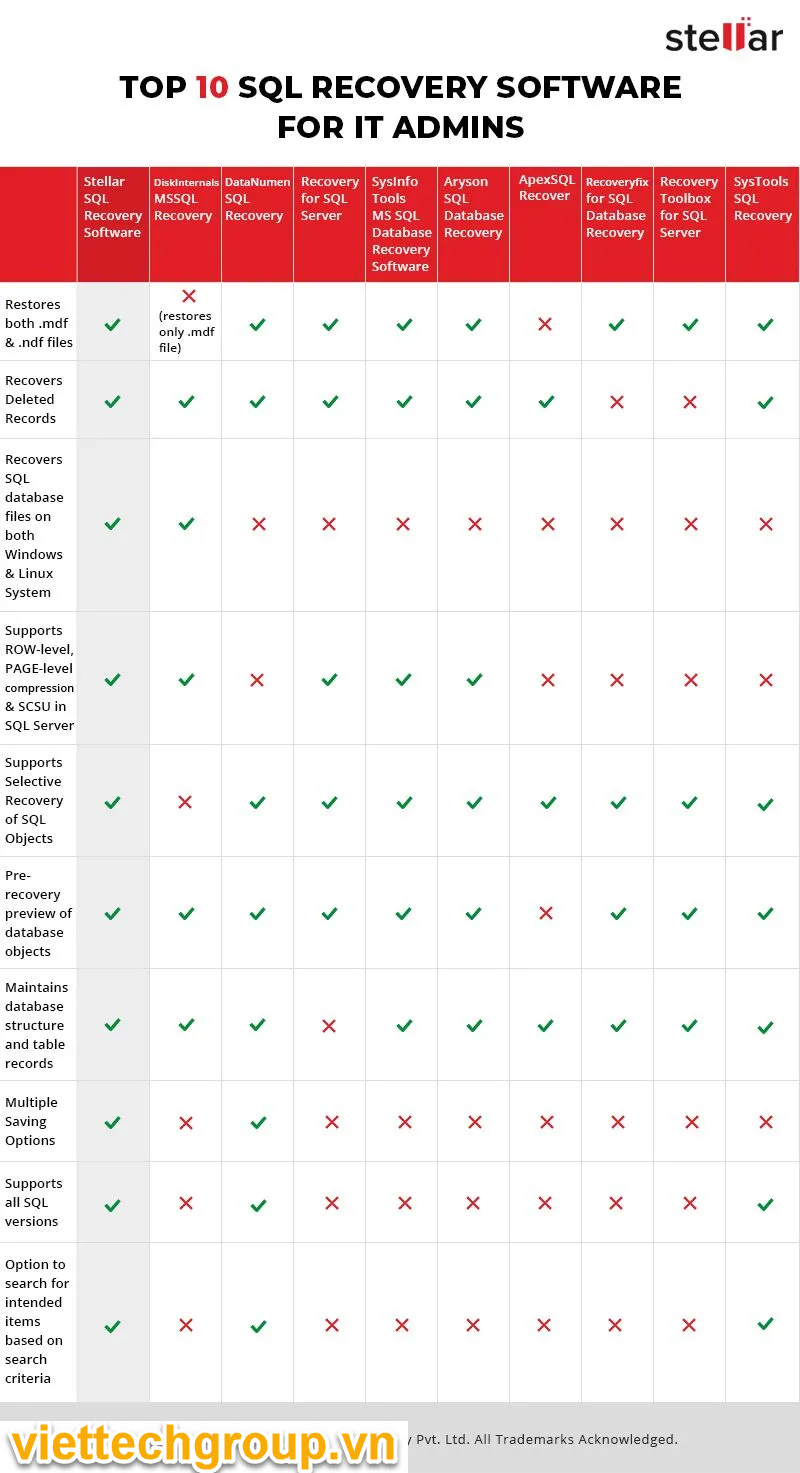
TRIỂN KHAI VMWARE VSPHERE REPLICATION TRÊN NỀN TẢNG ẢO HOÁ VAMWARE VSPHERE-P1- TỔNG QUAN
Tổng quan vSphere Replication
VMware vSphere Replication (VR) tồn tại từ năm 2012; phiên bản mới nhất là 8.2 cho vCenter/ESXi 6.7. hiện tại là vSphere Replication 8.8. cho vCenter/vSphere 8.0U2.
vSphere Replication có thể được sử dụng độc lập hoặc được bao gồm trong VMware Site Recovery Manager (SRM) cho các kế hoạch khắc phục thảm họa.
Giấy phép vSphere Replication được bao gồm trong vSphere Enterprise Plus, trong khi SRM là một sản phẩm độc lập và là giấy phép cho mỗi VM hoặc mỗi CPU (như một phần của vCloud Suite Enterprise).
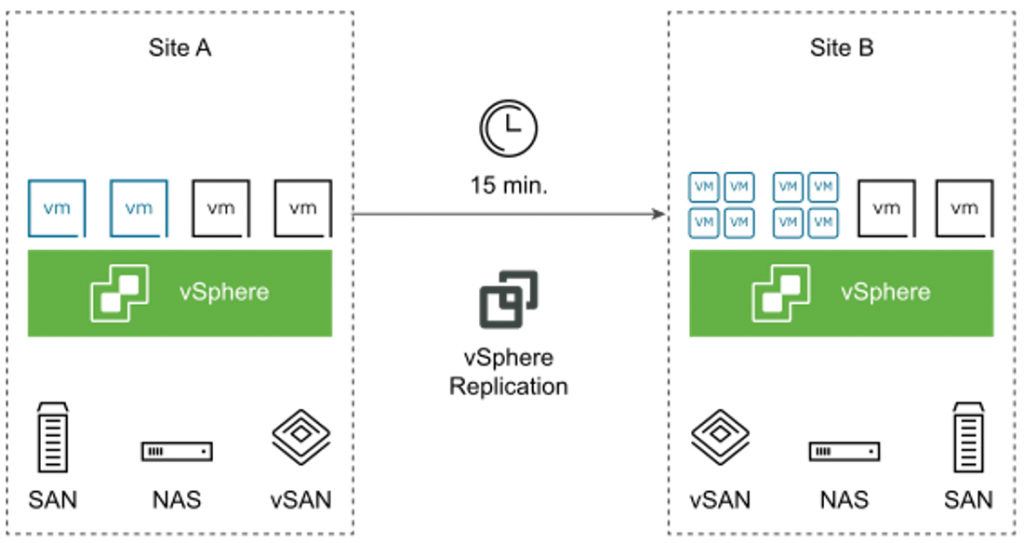
vSphere Replication bảo vệ Môi trường ảo VMware của bạn bằng cách sao chép môi trường (trang web) VMware của bạn sang một trang web phụ. vSphere Replication sử dụng Replication dựa trên mạng; SRM sử dụng bản sao dựa trên mảng lưu trữ hoặc Bản sao vSphere dựa trên mạng.
vSphere Replication là gì?
VMware vSphere Replication hoạt động với vCenter cung cấp khả năng sao chép và phục hồi máy ảo dựa trên bộ ảo hóa với tính năng bảo vệ dữ liệu với chi phí thấp hơn trên mỗi máy ảo.
vSphere Replication là giải pháp thay thế cho các sản phẩm đắt tiền hơn hoặc cần giấy phép của bên thứ ba để sao chép dựa trên bộ lưu trữ vì đây là bản sao dựa trên mạng.
Với vSphere Replication, khách hàng có thể sao chép từ trang này sang trang khác để tránh lỗi hoặc thời gian ngừng hoạt động trên Môi trường ảo của họ. Nó cũng có thể được sử dụng với kho dữ liệu VMware vSAN làm kho dữ liệu đích để sao chép.
vSphere Replication bảo vệ các máy ảo khỏi lỗi giữa các sites sau:
- Đồng bộ giữa các sites, từ site nguồn đến site đích
- Trong cùng một site, từ cluster này sang cluster khác
- Từ nhiều site nguồn đến một site đích từ xa được chia sẻ
Lợi ích khi sử dụng giải pháp vSphere Replication:
- Bảo vệ dữ liệu với chi phí thấp hơn trên mỗi máy ảo.
- Một giải pháp nhân rộng cho phép linh hoạt trong việc lựa chọn nhà cung cấp dịch vụ lưu trữ tại các địa điểm nguồn và đích.
- Tổng chi phí cho mỗi lần sao chép thấp hơn.
Sử dụng và tương thích với vSphere Replication
- Bạn có thể sử dụng vSphere Replication với vCenter Server Appliance hoặc với cài đặt vCenter Server tiêu chuẩn. Bạn có thể có Thiết bị máy chủ vCenter trên một site và cài đặt Máy chủ vCenter tiêu chuẩn trên site khác.
- vSphere Replication tương thích với phiên bản N-1 của vSphere Replication trên trang được ghép nối. Ví dụ: nếu phiên bản hiện tại của vSphere Replication là 8.8 thì phiên bản được hỗ trợ cho trang được ghép nối là 8.6 trở lên.
Site Recovery Client Plug-In
- vSphere Replication Appliance thêm một plug-in vào vSphere Client. Plug-in này cũng được chia sẻ với Site Recovery Manager và được đặt tên là Site Recovery.
- Bạn sử dụng plug-in máy khách Site Recovery để thực hiện tất cả các cấu hình vSphere Replication:
- Xem trạng thái vSphere Replication cho tất cả các phiên bản Máy chủ vCenter được đăng ký với cùng một Đăng nhập một lần vCenter.
- Mở giao diện người dùng Site Recovery.
- Xem tóm tắt các tham số cấu hình sao chép trên tab Tóm tắt của máy ảo được cấu hình để sao chép.
- Cấu hình lại các bản sao của một hoặc nhiều máy ảo bằng cách chọn VM và sử dụng menu ngữ cảnh.
Thành phần vSphere Replication Appliance
vSphere Replication Appliance cung cấp tất cả các thành phần mà vSphere Replication yêu cầu.
- Giao diện người dùng Site Recovery cung cấp đầy đủ chức năng để làm việc với vSphere Replication.
- Một plug-in cho vSphere Client cung cấp giao diện người dùng để khắc phục sự cố trạng thái của Bản sao vSphere và liên kết đến giao diện người dùng độc lập của Site Recovery.
- Cơ sở dữ liệu vPostgreSQL nhúng tiêu chuẩn của VMware lưu trữ thông tin quản lý và cấu hình sao chép. vSphere Replication không hỗ trợ cơ sở dữ liệu bên ngoài.
- A vSphere Replication management server:
- Cấu hình máy chủ vSphere Replication.
- Cho phép, quản lý và giám sát việc sao chép.
- Xác thực người dùng và kiểm tra quyền của họ để thực hiện các hoạt động Sao chép vSphere.
- Máy chủ vSphere Replication cung cấp cốt lõi của cơ sở hạ tầng vSphere Replication.
Local and Remote Sites
Trong cài đặt vSphere Replication điển hình, local site cung cấp các dịch vụ trung tâm dữ liệu quan trọng cho doanh nghiệp; remote site là một cơ sở thay thế, nơi có thể di chuyển các dịch vụ này đến khi cần thiết.
Local site có thể là bất kỳ site nào chứa vCenter Server, hỗ trợ nhu cầu kinh doanh quan trọng. Remote site có thể ở một địa điểm khác, hoặc trong cùng một cơ sở để thiết lập dự phòng. Các remote site thường nằm trong một cơ sở không có khả năng bị ảnh hưởng bởi môi trường, cơ sở hạ tầng thay đổi hoặc các xáo trộn khác, điều đó có thể ảnh hưởng đến local site.
vSphere Replication có các yêu cầu sau đối với môi trường vSphere® tại mỗi site:
- Mỗi site phải có ít nhất một trung tâm dữ liệu.
- Remote site phải có tài nguyên phần cứng, mạng và tài nguyên lưu trữ để hỗ trợ chứa các máy ảo và khối lượng công việc tương tự như ở local site.
- Các site phải được kết nối bằng mạng IP đáng tin cậy.
- Remote site phải có quyền truy cập vào các mạng (public và private) so sánh với các mạng trên local site, mặc dù không nhất thiết phải có cùng dải địa chỉ mạng.
Kết nối các local site và remote site
Trước khi sao chép các máy ảo giữa hai site, ta phải kết nối các site. Khi kết nối
site, người dùng tại cả hai site phải được chỉ định đặc quyền VRM remote.Manage VRM.
Khi kết nối các site là một phần của cùng vCenter Single Sign-On domain, ta chỉ cần chỉ định remote site, mà không cung cấp chi tiết xác thực, vì đã được đăng nhập.
Khi kết nối các site thuộc vCenter Single Sign-On domain khác nhau, vSphere
Replication Management Server phải đăng ký với Platform Services Controller trên remote site. Ta cần cung cấp chi tiết xác thực cho remote site, bao gồm IP hoặc FQDN của máy chủ nơi Platform Services Controller chạy và thông tin đăng nhập của người dùng.
Sau khi kết nối các site, ta có thể theo dõi trạng thái kết nối giữa chúng trong giao diện người dùng Site Recovery.
Cơ chế vSphere Replication hoạt động như thế nào?
- vSphere Replication Appliance được cài đặt tại nguồn và đích (nếu sao chép giữa các site) và tạo bản sao dựa trên máy chủ trên mỗi VM giữa các site với nhau.
- vSphere Replication tạo một bản sao của máy ảo trong mục tiêu bằng cách sử dụng các tác nhân VR bằng cách gửi các khối VM đã thay đổi giữa nguồn và đích.
- Quá trình sao chép này diễn ra độc lập với lớp lưu trữ, khác với cách SRM hoạt động khi sử dụng sao chép dựa trên mảng.
- Để tạo bản sao máy ảo ban đầu trên mục tiêu, vSphere Replication thực hiện đồng bộ hóa hoàn toàn máy ảo nguồn và bản sao bản sao của nó tại đích.
- Mức độ đồng bộ tồn tại giữa nguồn và đích phụ thuộc vào thời điểm khôi phục (RPO) và việc lưu giữ các phiên bản từ nhiều thời điểm (MPIT) để giữ các các bản sao chép trong cài đặt.
- Tất cả dữ liệu cấu hình vSphere Replication được lưu trong cơ sở dữ liệu nhúng. Bạn cũng có thể sử dụng Cơ sở dữ liệu bên ngoài để triển khai vSphere Replication.
- Theo mặc định, vSphere Replication có thể sử dụng ba kịch bản tiêu chuẩn:
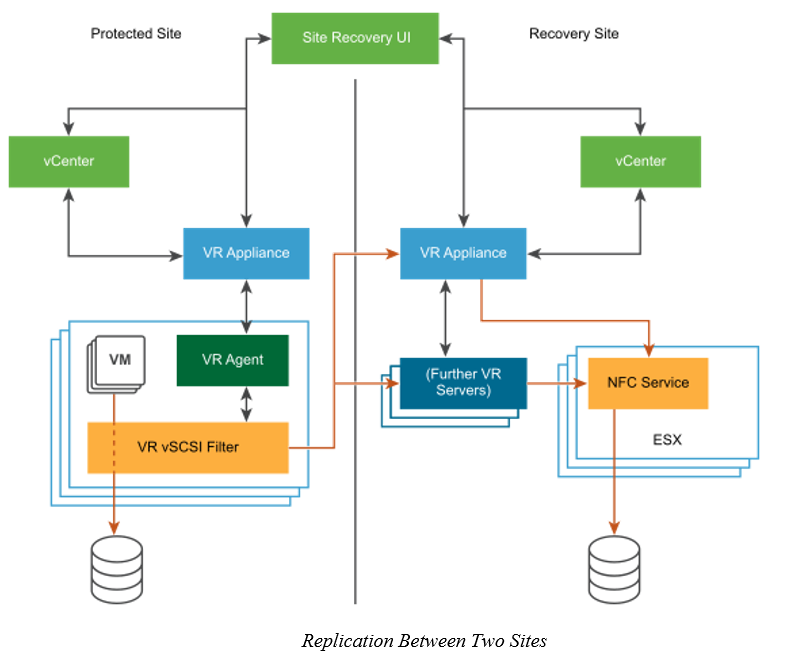
- Replication Between Two Sites
- Replication In a Single vCenter Server
- Replication to a Shared Target Site
Replication giữa 2 Sites
- Bạn cũng có thể sao chép một máy ảo giữa các kho dữ liệu trên cùng một Máy chủ vCenter. Trong cấu trúc liên kết đó, một Máy chủ vCenter quản lý các máy chủ tại nguồn và tại đích. Chỉ có một thiết bị vSphere Replication được triển khai trên một Máy chủ vCenter duy nhất. Bạn có thể thêm nhiều máy chủ vSphere Replication bổ sung trong một Máy chủ vCenter để sao chép các máy ảo sang các cụm khác.
- Để thực hiện khôi phục, Máy chủ vCenter quản lý kho dữ liệu đích, thiết bị vSphere Replication và mọi Máy chủ vSphere Replication bổ sung quản lý việc sao chép phải được thiết lập và chạy.
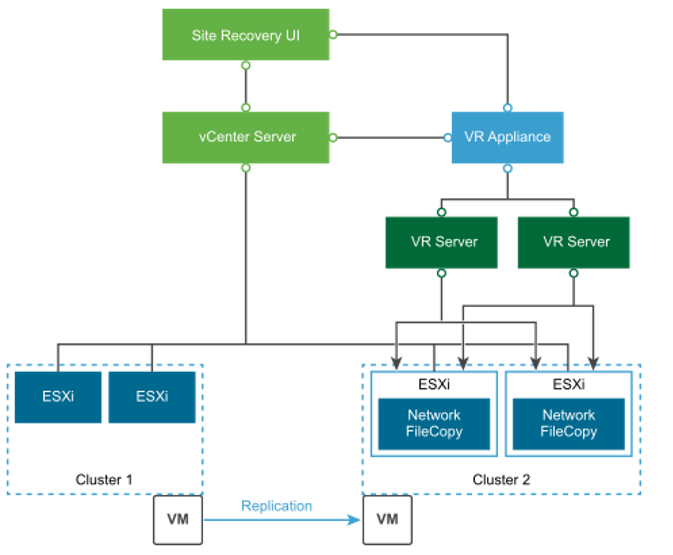
Replication trong cùng 1 vCenter Server
- Với kịch bản này, có thể sao chép các máy ảo bên trong vCenter.
- Trong trường hợp này, chỉ cần triển khai một Công cụ sao chép vSphere trong vCenter.
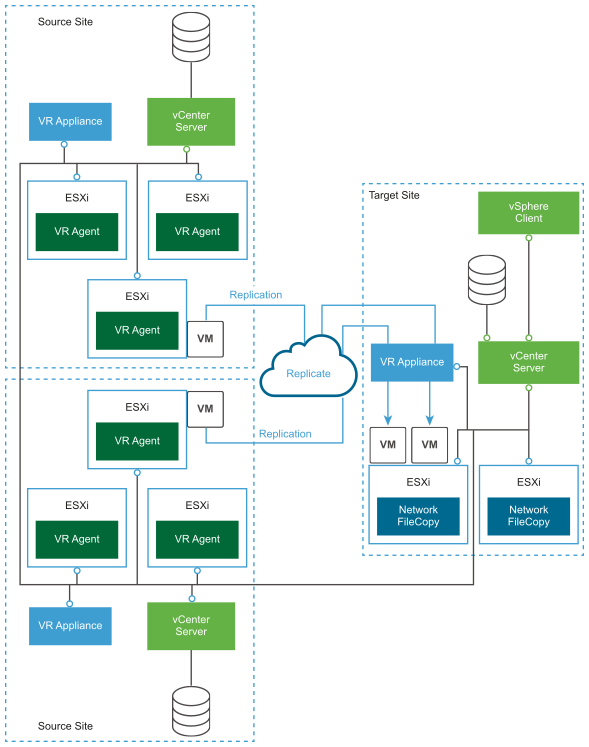
Replication đến các Site được chia sẻ
- Với kịch bản này, có thể sao chép các máy ảo sang một trang đích được chia sẻ. tức là chúng tôi có thể có nhiều vCenter sao chép sang (các) site của bạn hoặc thậm chí sao chép sang nhiều vCenter.
- Trong trường hợp này, chúng tôi cần triển khai vSphere Replication Appliance trong mỗi vCenter (trên nguồn và đích).
Giới hạn của giải pháp vSphere Replication
- Chỉ có thể triển khai một vSphere Replication (VR) trên mỗi vCenter
- Mỗi vSphere Replication chỉ có thể sao chép tối đa 2000 bản sao. Mỗi Thiết bị VR chỉ có thể quản lý 2000 VM
- Mỗi Máy chủ vSphere Replication chỉ có thể quản lý 200 Máy ảo trong tối đa 9 Máy chủ sao chép vSphere cho mỗi vSphere Replication appliance.
Giới hạn vSphere Replication – Virtual Machines Replication
- Không hỗ trợ ngữ cảnh FT VMs.
- VR chỉ có thể sao chép các máy ảo được bật nguồn và không thể sao chép các máy ảo đã tắt nguồn
- VR không đồng bộ được các Templates, Linked Clones, ISOs hoặc bất kỳ file không phải VM.
- VR chỉ có thể sao chép Đĩa ảo RDM được đặt ở chế độ Ảo
- Sao chép các cluster của MSCS không được hỗ trợ. VR không thể sao chép đĩa ở chế độ nhiều ổ ghi
- Bản sao của vCenter vApps không được hỗ trợ. Chỉ có thể sao chép VM bên trong vApps
- VR hỗ trợ tới 24 điểm khôi phục.
- Hỗ trợ sao chép máy ảo bằng snapshots; tuy nhiên, cây snapshot chỉ khả dụng và được tạo tại site đích (với khả năng khôi phục bằng điểm khôi phục snapshot)
Yêu cầu của vSphere Replication
- vSphere Replication được phân phối dưới dạng thiết bị ảo 64-bit được đóng gói ở định dạng .ovf. Nó được cấu hình để sử dụng CPU lõi kép hoặc lõi tứ, ổ cứng 16 GB và 17 GB và RAM 8 GB. Các máy chủ vSphere Replication bổ sung yêu cầu RAM 1 GB.
- Bạn phải triển khai thiết bị ảo trong môi trường Máy chủ vCenter bằng cách sử dụng trình hướng dẫn triển khai OVF trên máy chủ ESXi.
- vSphere Replication tiêu thụ CPU và bộ nhớ không đáng kể trên máy chủ nguồn ESXi và trên hệ điều hành khách của máy ảo được sao chép.
- Hỗ trợ cả Ipv4 và Ipv6.
- Lưu ý để đăng ký vSphere Replication bắt buộc phải sử dụng VirtualCenter.FQDN, nếu không sẽ bị lỗi nhé. Điều này đồng nghĩa các bạn phải tạo record A DNS local trỏ về Server VR.
Bản quyền vSphere Replication
Vì nó là 1 phần mở rộng của vSphere nên sẽ ăn theo license của vSphere:
- vSphere Essentials Plus
- vSphere Standard
- vSphere Enterprise
- vSphere Enterprise Plus
- vSphere Desktop
Replication Maximums for vSphere Replication 8.8
|
Item |
Maximum |
|---|---|
|
vSphere Replication appliances per vCenter Server instance. |
1 |
|
Maximum number of additional vSphere Replication servers per vSphere Replication. |
9 |
|
Maximum number of protected virtual machines per vCenter Server instance. |
4000 |
|
Maximum number of protected virtual machines per vSphere Replication appliance (by using the embedded vSphere Replication server.) |
400 |
|
Maximum number of protected virtual machines per vSphere Replication server. |
400 |
|
Maximum number of virtual machines configured for one replication at a time. |
20 |
|
Maximum number of protected virtual machines with 5 minute RPO per vCenter Server instance. |
500 |
|
Maximum number of protected virtual machines per vSphere Replication appliance on vSAN Express storage. |
1000 |
|
Maximum number of protected disks per virtual machine on ESXi 8.0 or earlier version. |
64 |
|
Maximum number of protected disks per virtual machine on ESXi 8.0 Update 1 or later version. |
256 |
|
Maximum number of protected disks per host. |
8192 |
Trên Đây Là Phần 1- Lý Thuyết Về Triển Khai Vmware Vsphere Replication Trên Nền Tảng Ảo Hoá Vamware Vsphere-P1
Các bạn có thể xem phần 2-Cài đặt Vmware Vsphere Replication Appliance phiên bản 8.8 tại đây nhé
Các bạn có thể xem phần 3-Cài đặt Vmware Vsphere Replication Appliance phiên bản 8.8 tại đây nhé
Phương Nguyễn dịch và viết